解説放送で話したのをメモしておきます。
(ABC231の解説放送のスクショ)
このツイートによると、ARC116E は xmas16H を少しいじると解けるらしいです。
かなりびっくりしたので証明をしようとしてみたら出来ました。
これら2つの問題はいずれも整数 N, K と N 頂点の木が与えられます。
(xmasの方は重み付きですが、重みなしの問題で考えます)
K 頂点選んで、各頂点から選ばれた頂点までの距離の最大値を最小化せよ
K+1 頂点選んで、選ばれた頂点間の距離の最小値を最大化せよ
双対感があると言われれば、そんな気もしなくはない?
これらの問題の答えをそれぞれ とすると、
が成り立つことを証明します。
とりあえずサンプルとしてパスグラフを考えてみると、
となり、たしかに成り立っています。(厳密に書きましたが、だいたいで良いです)
と
に分けて証明します。
を示す。
ある頂点から距離 以内の頂点の集合をエリアと呼ぶことにする。
エリアから 2 つの頂点を選ぶと、それらの距離は 以下になる。
ARC116E で を達成する解を 1 つとると
個のエリアで全頂点が被覆できるため、
互いの距離が 以上になるように頂点を選ぶとき、高々
頂点しか選ぶことができない。
よって、。
を示す。
ARC116E の判定問題は以下のアルゴリズムで解ける。
一方、xmas16H の判定問題は以下のアルゴリズムで解ける。
これらのアルゴリズムは 3. のみが異なるが、実は挙動はほぼ同じである。
特に、 が奇数の場合は
とすると完全に等しい。
祖先を選ぶか v を選ぶかの差は"祖先"以下の部分木内でしか生まれないが、
いずれにせよ"祖先"以下の部分木内の頂点は全て候補から消されるため、等しくなる。
(最も深いものを v としているのが効いている)
ARC116E の答えが であることから、
で上記のアルゴリズムを実行すると
個以上の頂点が選ばれるはずである。
つまり xmas16H で としたときの判定問題は True となるはずであり、
が示された。
ちなみに の方も同じように示すことも出来ますね。
ダイクストラ法、正しく書けてますか?
ダイクストラは少しのミスですぐ計算量が壊れたりするのですが、テストケースによっては意外に落ちにくく間違いに気づかないこともあります。
この記事では、よくあるミスとその撃墜ケースを紹介していきます。
この記事はどちらかと言うと問題準備をする方に読んでほしい記事です。
writerをする際は、ここで紹介する撃墜ケースをテストケースに入れるようにすると良いと思います。
SではなくTを始点にするという小手先技が考えられるので、逆向きバージョンも入れておくと尚良いでしょう。
ジェネレーターも置いておきます。
コード中の定数を書き換えたり入力で取れるようにしたり、出力形式を変えたりして使ってください。
念の為生成されたテストケースにもちゃんとvalidatorをかけて下さい。
まず、基本のダイクストラの実装は以下のようになります。
(getDist関数が本体です)
26行目の if (dist[v] != d) continue; を忘れるミスです。
うっかり忘れがち。
以下のようなケースで になります。

頂点 2~6 の部分が x 個ある場合:
1. 頂点 1 を始点とする
2. 頂点 2~6 が順に舐められ、毎回 dist[7] が更新される
3. 頂点 7 の番が来た頃には、キューの中に頂点 7 が x 個溜まっている
4. 頂点 7 をキューから取り出す度に x+1 本の辺を舐める
という流れになります。
(しっぽが付いているのは「dist[T] が確定したらbreak」枝刈り対策)
21行目の priority_queue<P, vector<P>, greater<P>> を priority_queue<P> のようにしてしまうミスです。
C++に不慣れな場合によくやってしまうミスかも知れません。
C++のpriority_queueは最大値がtopに来る仕様となっているため、比較関数を逆にしなければなりません。
このミスをしても一応正しい答えは出ますが、以下のようなケースで になります。

dist[2] が 127 から 1 ずつ減っていきます。
ちなみに、このケースで「pair<距離,頂点> ではなく pair<頂点,距離> にしてしまう」というミスも落とせます。
頂点数の制限が超絶厳しい場合は以下のようなケースが良いでしょう。
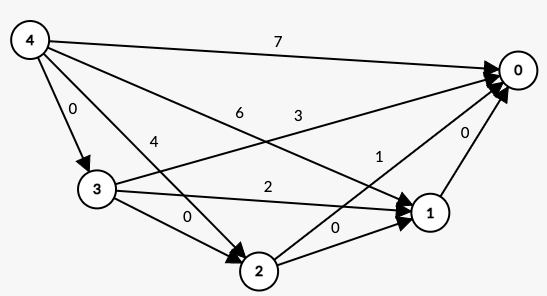
頂点 i から頂点 j へ の辺を張っています。
こうすることで「頂点 v を飛ばすとコストが 増える」という状況が実現できます。
挙動としては、頂点 4 から頂点 0 へのパスが辞書順に試されるような感じになります。
負辺のあるグラフでは(負閉路がなくても)ダイクストラは使えません。
おとなしくBellman-Fordなどを使いましょう。
以下のようなケースで になります。
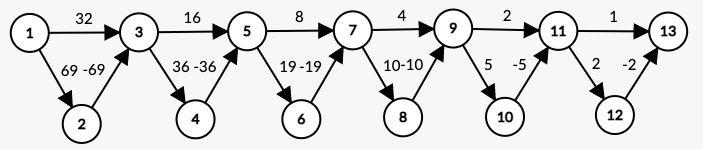
こちらも dist[13] が 63 から 1 ずつ減っていくはずです。
ちなみに、更新回数がちょうど X になるグラフを構築する問題が IPSC2015 で出題されていました。
dist[v]を更新するのを、キューに入れる時ではなく取り出した時にするとコードは少し短くなるのですが、距離を更新しない余計な情報をキューに突っ込んでしまうことになり、定数倍で落ちたりするので気をつけましょう。
Dijkstraの定数倍 - あなたは嘘つきですかと聞かれたら「YES」と答えるブログ
解説/講評編の続きです。
コンテスト運営の裏話などを記録しておきます。
イカれたお誕生日メンバーを紹介するぜ!
KCSの開発者にして、伝説の「帰ってきたお誕生日コンテスト」のwriterの1人でもある。KCSは偉大。今回は「帰ってきた」リスペクトの問題案が多かった印象。
お誕生日コンテスト運営常連。お誕生日よりは真面目寄りの「Xmasコンテスト」の運営常連でもある。ユーモア溢れるフレーバーテキストに定評があり、最近は小説に挑戦しているという噂がある。今回は文字・日本語系が多かった印象。
お誕生日コンテスト運営は「帰ってきた」「New Year」以外皆勤賞。japlj氏と同じくXmasもAtCoder回は皆勤賞。パズルっぽい問題と小ネタ系が多いと思う。
お誕生日コンテスト運営は「帰ってきた」以外皆勤賞。地理・言語学などに明るい。地理系・嫌がらせ系の問題が多い印象。(嫌がらせと言いつつちゃんと納得感がある所が憎めない)
こうして見ると、運営陣のお誕生日開催経験豊富すぎて草。
他の3人の間でお誕生日コンテストをやろうみたいな話が出ているところに、混ざりました。
参加するか/運営するかで迷いましたが、前回のNew Year Contestは優勝したので今回は運営かなーと決心しました。
日程が秋分に決まったのは、候補日をとりあえず決めようとなったときに、土日は急にratedコンテストが入ったりしがちなので祝日にしようということで、一番近い祝日を探した所、9/21,22だったからです。
個人的には翌日も祝日の方がいいかなーとちらっと思って敬老の日に投票しましたが、なんか秋分になりました。
お誕生日コンテストに敬老要素はあんまりないし、何より「秋分コンテスト」の響きが良すぎる。
7/26にslackに加入。
最初の頃はspreadsheetに問題案を各々書き込んで行ってて、自分が入った時にあったもの(で出題されたもの)は
あたり。そこから僕が自分のストックから
と軽いジャブを打って、すぐピクトセンスが実施される。
その後、
が追加される。(まさかこれらが全て出題されるとは...)
じわじわと問題案が追加されたりしていたり、一部問題案の準備(J、手紙、adblock、chessなど)が行われていたりした。
そして8月中旬、静かに、しかし確実に流れを動かした出来事が起こった。

「修正するのか、残念」ではないが?(後々kagamizを苦しめることになります)
8/22にコンテストページが生え、少し問題準備が加速。
同時にkagamiz氏によるKCSの開発も行われる。
最初期にKCSに置かれたのはadblockだった。
この頃のadblockはあみだくじではなく、例の鹿の絵のやつでバナー画像は入力に関する情報だった。
「画像2枚とも見えてからの方が本番すぎて、してやられた感が薄い」という指摘によって、この問題がadblockから独立する。
定期的に「帰ってきたお誕生日コンテスト」の話題で盛り上がる。


japlj氏がSoupの準備で激help状態になっていた。
そして9/6、ついにスープがslackに投下される。(その後もAIのトレーニング作業は続く...)
トップページのスタッフのコメントとかも書かれたりする。
japlj氏の怪文書コメントに含まれる「秋」の個数が最終的な問題数に偶然一致してて後に驚くことになる。
問題:以下の会話はどの問題に関するものでしょう?
人物1 『たまには問題文を普通にします』 人物2 『問題文「は」普通だった』
答え:嗚呼、恍恍惚惚 曠古、杲杲煌煌、兀兀甲骨
このあたりから準備作業が加速する。
小説が完成する。kindleに入れて読んだ。すごかった。
kagamizがスープとの長い格闘の末、ついに正解していた。
僕はかなり諦め気味でコナミコマンドを入力したが、何も起きなかった。
これがきっかけでスープにクエストが追加される。(今見たら「上上下下左右左右BA」でもクエストキー来るようになってるー!)
26問突破([問題の出現)が間近となる。

(後にめちゃくちゃ壊れます)
リチャード\d+世が完成。問題文を眺めて「あっ、これ予想以上に不可能なやつ来たな」と思った。
これを2:46に通したcatupperまじですげぇよ...(結局単独AC)
twitterにシークヮーサーのやつが流れててあ〜となる。
そしてついに26問の壁を突破する。

僕はこれを見て密かに「a問題が見たい...」と思ってしまった。思ってしまったんだ。(犯行予告)
pictureが難しすぎると話題に。
元の画像これだからな。

僕もほとんど分かってはいたけど「フェンスを置くたびに1円かかる」だと思ってて分からなかった。
各所からのツッコミにより現在の絵に改善されました。感謝して下さい。

S問題の話題からKCS自由過ぎるやろwって話になって、軽い気持ちで、

こう言ったら、現状の機能だけでも実現できることに気付き、実装...
もっとコンテスト中に気づいてびっくりして欲しかったね。
\ 問題のジャッジがなんかおかしいので調査してもらった所、KCSがめちゃくちゃに壊れていることが判明。(それはそう)
これはkagamizは悪くない、snukeとかいう頭のおかしいお誕生日野郎が明らかに悪い。

再 犯
「a問題が見たい」じゃあないんだよ。(でもaは壊れなかった)
a問題が見たかった僕は怒涛の3連投(数列クイズ、Echo、くそなぞなぞ)
前2つは「次回に温存しようかな〜」くらいのものだったけど、くそなぞなぞは即席でひねり出したまさにクソ問題です。
まぁでも「くそなぞなぞ」が問題一覧に並んでたら嬉しいよね?
ただ内容は「秋分」から即興で作った4問とストックにあったのから競プロ要素があるのを出しただけなのでかなり質は低めだったと思います(反省)
「鉄アレイ」はまあまあかな?「スタッフオーバー苦労」はそこそこ好きだったんだけど、なんかガチ勢によるとどっかで見たことあるらしくとても悲しい。
ストックにはちゃんと面白いくそなぞなぞもあるので、いつかお披露目したいね。
あと、Echoは性質上100ケースくらいは欲しいけど、ジャッジキューを苦しめる要因の1つになって申し訳なかったね。
ここら辺までで細かい部分以外の問題準備は終了した。
THE EMPTYを追加し、無事a問題達成。
と思っていたらtozanがRealtime Tozangya(後のR問題)を隠し持っていたらしく、b問題達成。
これで問題数が決まったので、配点決定および問題並べ替え閣議を実施。
結構色々話した気がするけどdiscord通話なので記録は残っていない。
問題順は、意外に結構ちゃんと理由がある配置が多いので考察してみて。
宣伝もこのあたりから開始。
絵しりとり実施
トップページのコメントをちゃんと書いたりmarquee実装したりする。
japlj氏がtester業をちょっとやってた
運営一緒にやってていつも思うけど、優秀過ぎる・・・

あみだくじを画像解析で解いて遊んだ。(おわかりいただけただろうか)
手紙とかも解いた。楽しかった。
自分もスープ解いときたいなーと思ったけど全然駄目で、おもむろに質問相手を変更しました。
その結果、入力全部(2進or3進で一桁ずつ特定していけばO(桁数)回で全部特定できます)と、一部の出力が分かった。
けど、OEISで歯抜け検索ができないと思っていて解けなかった。(_を使うと良かったんですねぇ〜)
(これのおかげでOEISという単語を思いつけてなんとか解けたけど)
みんはやを使って宣伝をしたりした。
こんな"すごい"のをぶつけられた参加者がいかに驚いてくれるか、ワクワクして来ました。
秋分コンテストを開催しました!
スタッフ:japlj,kagamiz,snuke,tozangezan
あの伝説のジャッジシステムKCSが復活し、またこうして新たなお誕生日コンテストが開催されたことを喜ばしく思います(?)
ただ復活しただけでなく新たな進化を遂げ、自由度がさらに高まったKCSでwriter陣は大暴れをいたしましたが、びっくりしていただけたでしょうか?
その上で、楽しんでいただけた問題が1つでもあったならば幸いです。
過去のお誕生日コンテストの定番シリーズで、どこかに隠されたキーワードを探すという問題です。
例えば、問題ページのhtmlのコメントとか、問題ページに限らずトップページのどこかとか、隠し場所は色々考えられます。
ただ、ほとんどの隠し場所はすでにHackerRank時代にやり尽くしているので、今回はKCSにしかない場所に隠すことにしました。
というわけで、通知一覧をご覧ください。
ちなみに、https://kcs.miz-miz.biz/static/2000/the-empty.html にURLをエスパーしてたどり着くとクエストキーが得られます。(4通りの表記ゆれをカバーしてます)
さすがに無理だろうと思っていましたが、案の定たどり着いた人は0でした。
KCSは画像だけでなくhtmlもアップロードできるんですねぇ〜〜
想定解
2番で「一日千秋」を連想して「千分の一」と答えるとクエストキーが得られます。
1人くらいは通じ合える人がいるかな〜と思っていたら、1人いて嬉しい。
正は10^40なので、100000000000000000000(10^20)が答えです。
「垓」という答えを見て「たしかに」となりました。たしかに。
ja.wikipedia.org
の図をご覧ください。
正規表現を使うと楽です。
ただし、C++でやる場合は気をつけて下さい。
https://kcs.miz-miz.biz/contest/2000/code/103529
このコードどこがおかしいかわかりますか?
実は "ー?" の部分が駄目で、"ー" はマルチバイト文字なのでその最後の1バイト分にしか '?' がかからなくてすごいことになるっぽいです。
("(ー)?" ならok)
ここにも実はクエストがあって、ソースを見て画像のURLを見ると、この画像はかぼすであることがわかります。
いらすとやでシークワーサーの画像を探してきて、そのファイル名からURLをエスパーするとクエストキーが得られます。
ちなみに似たシリーズとしてすだちの画像もいらすとやにあるらしく、こっちにアクセスするとさらにクエストキー入手です。
tozangezan考案で、最初ちゃんとシークワーサーの画像を問題文に貼ってたのにも関わらずなぜかすだちの画像のURLにアクセスしようとしたらしい(当然そんなものは置いてなかった)
(それにしても "fruit_shi-kuwa-sa_shikuwasa.png" って言う命名なんなんだ?)
ちなみにこの図はQuizKnockで知ったんだっけな。コンテスト数日前にtwitterでも流れてて「あっ...」ってなったけどまぁいいやとなった。
ジャッジコードでソースコードを取得できる機能がKCSに生えたということで、お誕生日コンテスト用問題ストックにあったのを放出。
'/' を使わず割り算をする問題です。
pythonやc++で "div" を使うという解法もありますが、"div" を含む場合は50点にしました。
それ以外にもいくらでもやりようはあります。
例えばO(log A)でアルゴリズムの力に頼って足し算と掛け算だけでやるのもありです。
他にもpythonのevalを使って print(eval(input().replace(' ',chr(47)*2))) とやるのもありですね。
#define waru di##v とかもありですね。
個人的にチェスが結構好きなので出題してみました。
海外では一番メジャーなボードゲームなだけあって、チェスネタはプロコンでもたまに出題されますね。
ちなみに初期盤面がジャッジコード内でしっかりチェックされていることを考えると他のバリアントはCrazyhouseしか使えなさそうですが、これもなんかFENに持ち駒の情報が付いてしまって使えません。
python-chessの実装を読んだりすると「パス」に相当する "z0" (null move) というのが使えるようで、これは自分のキングにチェックかかってようが可能みたいで、これを使うと大体なんでもやりたい放題になります。
全く予想外でしたね... これは参加者の方が一枚上手でした。
実は6もAntichessで頑張れば解けるみたいです。(ただしgiveawayで提出する必要はある)
これを見つけて感動したので、急遽クエストキーを追加しました。(その後 z0 解にクエストキーが取られてびっくりした)
意外と気づかれないもんですねぇ。
yesと答えた後に得点を書き換えようとしてみて下さい。
びっくりしてもらえましたか?
仕組み(白文字):KCSはVERDICTにhtmlコードを仕込めるのでそこにjsをガッツリ書きました
ちなみに、変な出力をすると "Answer Yes or No." と言われるので、"Yes or No" とそのまま答えるとクエストキー "kuso_mitaina_parse_wo_suruna" が得られます。
OEISして終わり!かと思いきや、OEISが間違っています。しかもかなりガバ。
この数列は、へやわけというパズルで中央の正方形の部屋に最大いくつ黒マスが入れられるか、というやつです。
解法としては
historyのところに修正提案がちゃんとあるらしい(情報提供:amylaseさん)
ちなみに似たのがもう一個あって、そっちもはちゃめちゃ。
競プロ。
とりあえず提出してみると、-135点が来ます。
よく見ると、testsetが大量に設定されており、その中には負の配点のものもあります。
つまり、正解するテストケースを上手く選ぶ最適化問題というわけです。
構造をよく見ると、
という構造になっています。
この最大化はmincutに帰着できます。
詳細に解説はしませんが、この問題などが参考になるのではないでしょうか?
ちなみに、ちゃんとテストセットの構造を見て計算しないとなかなか正の点すら得られません。
なんとなく得点効率が良さそうなやつだけ選ぶ貪欲で100点ちょいが来ます。
マラソンでも満点行けるんかな?と思ってましたがちゃんと焼き鈍したりしないと意外に満点はきついっぽい?(199で止まる人がちらほら)
ちなみに最小化は多分多項式とかでは解けないと思いますが、IP(整数計画問題)に落としてソルバを使えば爆速で答えが求まります。(-1644点 (笑))
-1644点を取った人はclimpetさんただ一人でした。(クエストを設定しようと思ってましたが、キーワードを与える方法がなくて断念しました)
ちなみに最適解は2通りだけみたいです。(14,24,42をflip)
ちなみにHackerRank恒例の負の得点はKCSは対応していません。(順位計算時に0とのmaxが取られる)
というかHackerRankが異常で、なんで「負の得点が取れて、一回取ってしまうと撤回不可能」みたいなことができるかというと、「問題の点数は0~1の実数で出して、順位計算時にそのmaxを取ったものに配点の値を掛ける」というシステムだから(多分)です。
何気なくしたネタツイートが不思議な展開になって面白かったので。
togetter.com
New Year Contest 2020に参加しました。
24時間26問で、出題される問題はノンジャンルなんでもありというお祭りみたいなコンテストです。
2687.66点で優勝しました。
AM8時あたりの時点では結構2位に差があったけど、じわじわ追い上げられて結局sugimさんに67点差まで詰められて危なかった。
{kind=link}
{kind=link}