ダイクストラ法のよくあるミスと落し方
ダイクストラ法、正しく書けてますか?
ダイクストラは少しのミスですぐ計算量が壊れたりするのですが、テストケースによっては意外に落ちにくく間違いに気づかないこともあります。
この記事では、よくあるミスとその撃墜ケースを紹介していきます。
この記事はどちらかと言うと問題準備をする方に読んでほしい記事です。
writerをする際は、ここで紹介する撃墜ケースをテストケースに入れるようにすると良いと思います。
SではなくTを始点にするという小手先技が考えられるので、逆向きバージョンも入れておくと尚良いでしょう。
ジェネレーターも置いておきます。
コード中の定数を書き換えたり入力で取れるようにしたり、出力形式を変えたりして使ってください。
念の為生成されたテストケースにもちゃんとvalidatorをかけて下さい。
目次
- 既に見た頂点のcontinue忘れ:
- 最大ヒープを使う:
- 負辺のあるグラフで使う:
まず、基本のダイクストラの実装は以下のようになります。
(getDist関数が本体です)
既に見た頂点のcontinue忘れ
26行目の if (dist[v] != d) continue; を忘れるミスです。
うっかり忘れがち。
以下のようなケースで になります。

頂点 2~6 の部分が x 個ある場合:
1. 頂点 1 を始点とする
2. 頂点 2~6 が順に舐められ、毎回 dist[7] が更新される
3. 頂点 7 の番が来た頃には、キューの中に頂点 7 が x 個溜まっている
4. 頂点 7 をキューから取り出す度に x+1 本の辺を舐める
という流れになります。
(しっぽが付いているのは「dist[T] が確定したらbreak」枝刈り対策)
最大ヒープを使う
21行目の priority_queue<P, vector<P>, greater<P>> を priority_queue<P> のようにしてしまうミスです。
C++に不慣れな場合によくやってしまうミスかも知れません。
C++のpriority_queueは最大値がtopに来る仕様となっているため、比較関数を逆にしなければなりません。
このミスをしても一応正しい答えは出ますが、以下のようなケースで になります。

dist[2] が 127 から 1 ずつ減っていきます。
ちなみに、このケースで「pair<距離,頂点> ではなく pair<頂点,距離> にしてしまう」というミスも落とせます。
別パターン(おまけ)
頂点数の制限が超絶厳しい場合は以下のようなケースが良いでしょう。
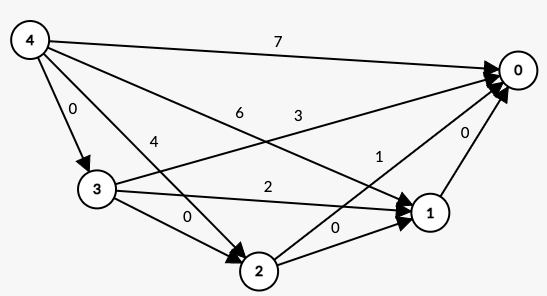
頂点 i から頂点 j へ の辺を張っています。
こうすることで「頂点 v を飛ばすとコストが 増える」という状況が実現できます。
挙動としては、頂点 4 から頂点 0 へのパスが辞書順に試されるような感じになります。
負辺のあるグラフで使う
負辺のあるグラフでは(負閉路がなくても)ダイクストラは使えません。
おとなしくBellman-Fordなどを使いましょう。
以下のようなケースで になります。
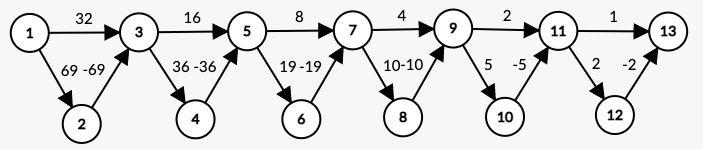
こちらも dist[13] が 63 から 1 ずつ減っていくはずです。
ちなみに、更新回数がちょうど X になるグラフを構築する問題が IPSC2015 で出題されていました。
おまけ(定数倍)
dist[v]を更新するのを、キューに入れる時ではなく取り出した時にするとコードは少し短くなるのですが、距離を更新しない余計な情報をキューに突っ込んでしまうことになり、定数倍で落ちたりするので気をつけましょう。
Dijkstraの定数倍 - あなたは嘘つきですかと聞かれたら「YES」と答えるブログ