この記事はCompetitive Programming Advent Calendar 2018の46日目の記事として書かれました(嘘)
最近、木上のアルゴリズムの面白い計算量解析が2つ話題になったのでまとめておきます。
予備知識
まず、https://web.archive.org/web/20150819082918/https://topcoder.g.hatena.ne.jp/iwiwi/20120428/1335635594 について復習します。
iwiさんのブログとは違う、より直感的な解析方法も紹介します。
以下の問題を考えます。
N 頂点の木が与えられる。
頂点 1 を含む頂点数 K の根付き木の個数を求めよ。
制約:1 ≦ K ≦ N ≦ 3000
典型的な木DPの問題です。
解法は以下の通りです。(解法の細かい説明は本題ではないので追わなくて大丈夫です)
頂点 1 を根とした根付き木にして以下のようなdpテーブルをボトムアップに計算していく。
・dp[v][i] = 頂点 v を根とする頂点数 i の根付き木の個数
例えばpythonで書くと以下の通りです。
def dfs(v): sz[v] = 1 dp[v] = [0]*(sz[v]+1) dp[v][1] = 1 for u in to[v]: dfs(u) merged = [0]*(sz[v]+sz[u]+1) for i in range(sz[v]+1): for j in range(sz[u]+1): merged[i+j] += dp[v][i]*dp[u][j]%mod sz[v] += sz[u] dp[v] = merged dp[v][0] = 1
(変数宣言、入出力などは省略しています)
このアルゴリズムの計算量について考えていきます。
最も重い部分は i,j に関する二重ループの部分です。
ここの計算量は O(sz[v] * sz[u]) です。
つまり、サイズがそれぞれ a, b のdpテーブルをマージするときに O(ab) の計算量がかかっています。
これらを合計すると一見 O(N^3) の計算量が掛かるように思えます。
しかし、実は全体で O(N^2) になっているのです。
この計算量を解析するために以下のような問題を考えます。
N 個のグループがあり、初めは各グループに頂点が1つずつ含まれています。
これらをマージしていき、最終的に1つのグループにしたいです。
グループ A,B をマージするとき、A に含まれる頂点と B に含まれる頂点の間を結ぶような辺を全て追加します。(つまり、|A|*|B| 本の辺を追加します)
マージの順番を工夫したとき、追加する辺の本数は最大で何本でしょうか?
例えば以下のような流れになります。
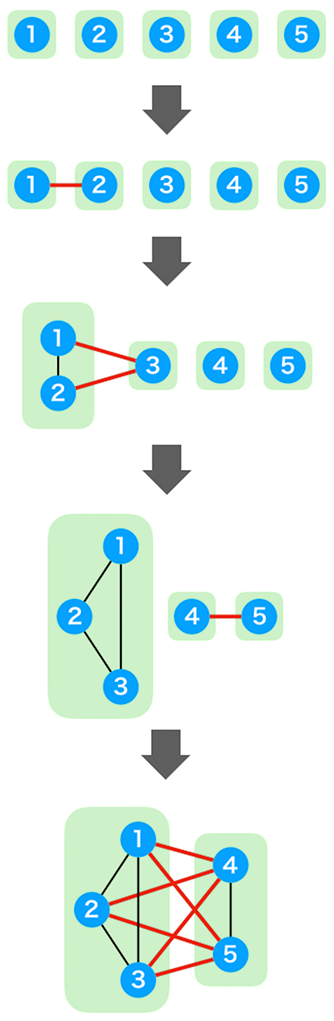
答えは「どのような順番でマージしても完全グラフになるので、N*(N-1)/2」でした。
(どの2頂点間の辺についてもちょうど1回ずつ追加されるため)
この問題が計算量解析にどう関係しているかは、以下の2つを比較すれば分かるでしょう。
- サイズがそれぞれ a, b のdpテーブルをマージするときに O(ab) の計算量がかかる
- サイズがそれぞれ a, b のグループをマージするときに ab 本の辺を追加する
辺の本数がそのまま計算量を表しているのです。
というわけで先ほどのアルゴリズムの計算量は O(N^2) なのでした。
本編
予備知識だけでもそれなりのボリュームでしたが続けます。
以下のような問題を考えます。
N 頂点の木が与えられる。
頂点 1 を含む頂点数 K の根付き木の個数を求めよ。
制約:1 ≦ N ≦ 10^5, 1 ≦ K ≦ 500
先ほどと同じようなDPをpythonで書くと以下のようになります。
def dfs(v): global ans sz[v] = 1 dp[v] = [0]*(sz[v]+1) dp[v][1] = 1 for u in to[v]: dfs(u) merged = [0]*(sz[v]+sz[u]+1) for i in range(sz[v]+1): for j in range(sz[u]+1): merged[i+j] += dp[v][i]*dp[u][j]%mod sz[v] += sz[u] dp[v] = merged if sz[v] > K: sz[v] = K dp[v] = dp[v][:K+1] if sz[v] >= K: ans += dp[v][K] ans %= mod dp[v][0] = 1
要点は、dpテーブルのサイズが K を超えたら K になるようにカットしている点です。
このアルゴリズムの計算量を解析するために、簡略化した以下の問題を考えます。
N 個の集合があり、初めは各集合のサイズが1です。
これらをマージしていき、最終的に1つの集合にしたいです。
グループ A,B をマージするとき、min(|A|, K) * min(|B|, K) のコストがかかります。
マージの順番を工夫したとき、コストの合計は最大でいくらになるでしょうか?
追記:下の方により簡潔な解析方法を書きました。
サイズが K 未満の集合を「小」、K 以上の集合を「大」と表すことにして場合分けをします。
小と大のマージ
小と大のマージコストは「(小のサイズ) * K」です。
元(集合の要素)に注目すると、各元が小-大マージの小の元として選ばれる回数は高々1回です。
また、元の個数は N なので Σ(小のサイズ) は N で抑えられます。
よって、小と大のマージコストの合計が O(NK) であることが言えました。
追記
より直感的で場合分けもない解析方法を知ったので書いておきます。
予備知識のところで使った手法に似ています。
マージの過程を二分木のような形で表します。
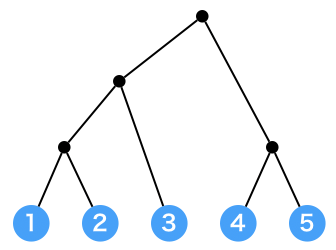
で、マージするときに左のグループ内の右からK個と右のグループ内の左からK個の頂点の間に辺を張ることを考えます。
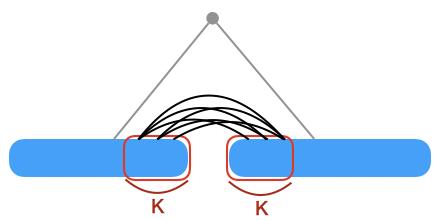
- 各頂点間には高々1回しか辺が張られない
- 距離が2K以上離れた頂点との間には辺は張られない
ということが言えるので、辺の本数の合計はO(NK)となります。
あとがき
結構長く競プロをやってるつもりだけど、この計算量今まで知らなかった。面白い。
場合分けをしない良い感じの解析方法を見つけたりしたら教えてください。(上の追記参照)
うむ,やっぱあまりに汎用性が高いので僕が知らなかっただけで常識なのではないかと思い始めた.
ちなみにこれを知ったきっかけはHello 2019 Gでした。
(※ そのままdpしてもダメなので式変形などで工夫をする必要はあります)




