最近 Mo's Algorithm - Codeforces をよく目にする気がします。
興味深いアルゴリズムではありますが、より良いアルゴリズムがあります。
追記:「上位互換」と煽っていますが、実装量・定数倍の面から、Moが使えるときはMoを使ったほうが良いでしょう
Mo
まずはMo's algorithmの概要を説明しておきます。
Mo's algorithmは以下のような問題に適したアルゴリズムです。
長さNの数列に対し、Q回の区間クエリを処理する。 ただし、[l, middle) と [middle, r) の結果をマージすることはできない。(できるならsegtreeでいい) ・値の追加操作ができる。([l, r) から [l-1, r) や [l, r+1) が求まる) ・値の削除操作ができる。([l, r) から [l+1, r) や [l, r-1) が求まる)
つまり、区間の結果をマージする操作がlogとかでできず、区間を1つ伸ばしたり縮めたりするのがlogとかでできる場合。
クエリをリンク先の記事のソースコードのようにソートして、区間を伸縮しながら処理するというのがこのアルゴリズム。
クエリの l と r を2次元座標にプロットすると一目瞭然です。
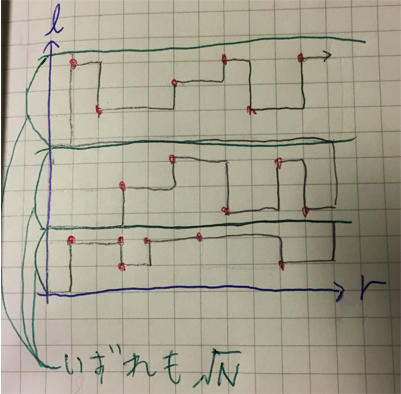
(本当は l >= r の領域には点がありませんが、本質的な差はありません)
- 赤点はクエリを、黒線は区間の伸縮の様子を表しています。
- 緑線で区切られた領域は√N個あり、それぞれの高さは√Nです。
このとき、横移動(rを増減させる操作)に注目すると、左端から右端までの逆戻りなしの往復が√N回となるため、全体の長さは O(N√N) となります。
そして、縦移動(lを増減させる操作)に注目すると、ひとつの点に対して高々√Nなので、全体の長さは O(Q√N) となります。
つまり、計算量は O( (N+Q) √N * [伸縮1回の計算量] ) となります。(厳密には + Q log Q だけど本質ではない)
追記:区切る領域の個数を√Q個(高さはN/√Q)にすると計算量はO(N√Q)になるらしい、なるほど。(横移動はそのままで、縦移動はQN/√QでこれもN√Q)
こっちの計算量の方が上記よりも良いこと( O(N√Q) ≦ O((N+Q)√N) )を示しておく。
両辺を√Nで割って O(√N√Q) ≦ O(N+Q)、両辺二乗して O(NQ) ≦ O(N^2+Q^2+NQ)。
実装
実装自体はイメージよりもだいぶ軽いです。
int n; // 数列の長さ int q; // クエリ数 vector<int> l(q), r(q); // クエリの[l,r) /* 入力 */ // ソート int sq = max(1, int(n/sqrt(q))); vector<int> qi(q); for (int i = 0; i < q; ++i) qi[i] = i; sort(qi.begin(), qi.end(), [&](int i, int j) { // クエリの順番をpair(l/sq,r)でソート if (l[i]/sq != l[j]/sq) return l[i] < l[j]; return r[i] < r[j]; }); // クエリの処理 // add(i)は追加操作、del(i)は削除操作 int nl = 0, nr = 0; // [nl,nr) for (int i : qi) { while (nl > l[i]) --nl, add(nl); while (nr < r[i]) add(nr), ++nr; while (nl < l[i]) del(nl), ++nl; while (nr > r[i]) --nr, del(nr); /* クエリの結果計算 */ }
上位互換
Moの上位互換のアルゴリズムは上記のようなクエリを処理できます。しかも、削除操作ができる必要がありません。
その代わり、データ構造にはrollback(+snapshot)メソッドを実装する必要があります。
rollbackはその名の通り、snapshotを撮った位置までデータ構造の状態を巻き戻すメソッドです。
rollbackは、 <配列のindex, 元の値> のペアを記録しておいて時系列の逆順に戻すようにやります。データ構造が複雑な場合はindexの代わりにポインタで持つと良さそう。
これは追加操作と同じ計算量になります。なぜなら、追加操作の計算量がO(log N) だとすると、追加操作で行われる代入の回数は高々O(log N)にしかならないためです。
アルゴリズム
まず、長さが√N以下のクエリを愚直に全て処理します。(クエリあたり O(√N * [追加操作の計算量] ))
残りの長さが√Nより大きいクエリを l/√N の商で仕分けます。
それぞれのグループのクエリたちの処理は以下のように行います。
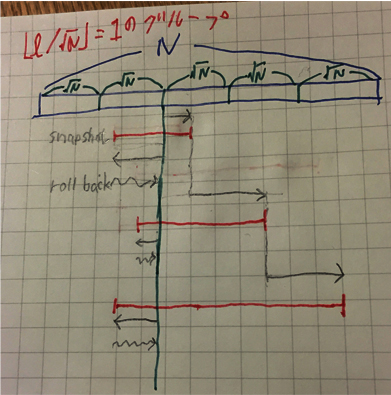
1. グループ内のクエリ区間を右端の昇順にソートしておく。
2. グループ内のクエリ区間の左端をギリギリ超えるような √N の倍数を X とする。(緑の縦線の位置)
3. [X,X) から始めて、右端を1つずつ伸ばしていく。
4. 現在の右端がクエリ区間の右端と一致したらsnapshotを撮る。
5. 左端をクエリ区間の左端まで伸ばす。
6. rollbackして 3. に戻る。
右端を伸ばす回数は1グループあたり O(N) なので、全体で O(N √N) 回です。
左端を伸ばす回数は1クエリあたり高々 O(√N) なので、全体で O(Q √N) 回です。
これらをまとめると、計算量はこれまた O( (N+Q) √N * [追加操作の計算量] ) となります。
追記:Moと同様に、√Q個に分割するとO(N √Q * [追加操作の計算量])になって計算量が真に良くなります。
以下はrollback(とsnapshot)がついたUnionFindの実装例です。
struct UF { vector<int> d; // 根の場合は高さ*-1、子の場合は親の番号が入る vector<pair<int,int>> history; UF(){} UF(int mx):d(mx,-1){} int root(int x){ if(d[x] < 0) return x; return root(d[x]); } void unite(int x, int y){ x = root(x); y = root(y); if(x == y) return; if(d[x] > d[y]) swap(x,y); if(d[x] == d[y]) { history.pb(make_pair(x,d[x])); d[x]--; } history.pb(make_pair(y,d[y])); d[y] = x; } void snapshot() { history.clear(); } void rollback() { while (history.size()) { d[history.back().first] = history.back().second; history.pop_back(); } } };
このアルゴリズムでこれ(UF+区間クエリ)とかが解けます。
ちなみにこれ自分で考えて喜んでたら、Moの記事のコメント欄にも載ってました。
名前があった方がウケがいいらしいので、Rollback平方分割とでも呼ぶことにしようかな。
ちなみに、追加クエリが均し計算量の場合は注意が必要です。
まとめ
汎用性の高い Rollback平方分割 の方を覚えておいて損はないと思います。
Mo's algorithmも、上の方にある図を覚えておけばすぐに思いつける程度のものだし、忘れる必要はないです。
ただ、実用上では必ずしも上位互換というわけではなく、削除操作が出来てかつ「削除操作の実装 < 分割+rollbackの実装」の場合は実装量の面でMo's algorithmの方がいいかもしれません。追記:あと、定数倍もMoの方が良いっぽい。